
- 83% of people who applied for a loan are skilled or highly skilled.
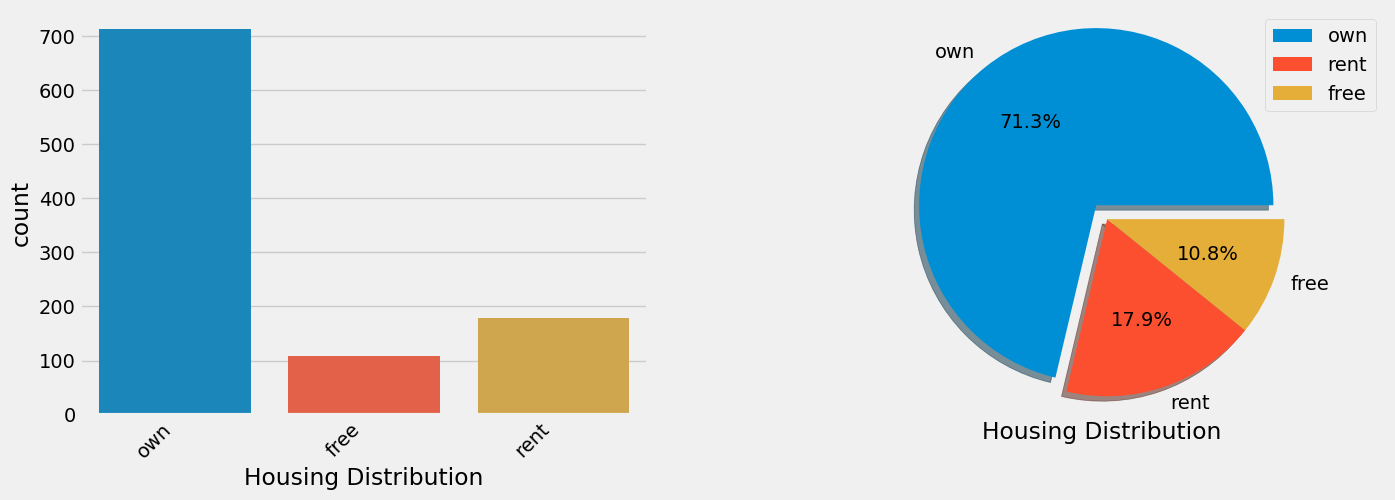
- People with their own houses are the primary customer type (71.3%).
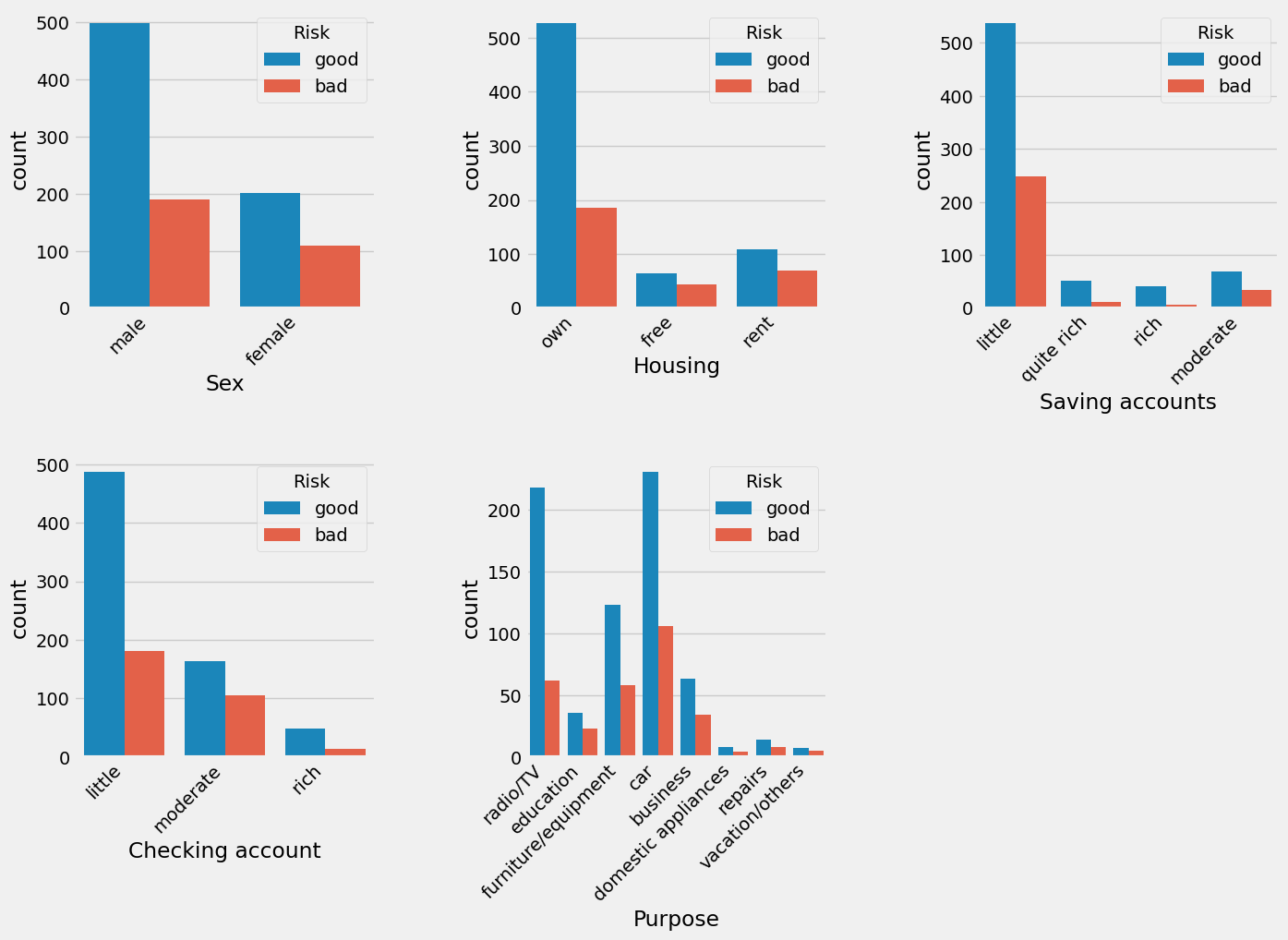
- Most loan applications are to buy a car (33.7%), followed by purchasing a radio/TV (28.0%).
- Most of the customers have a small checking account (66.8%).
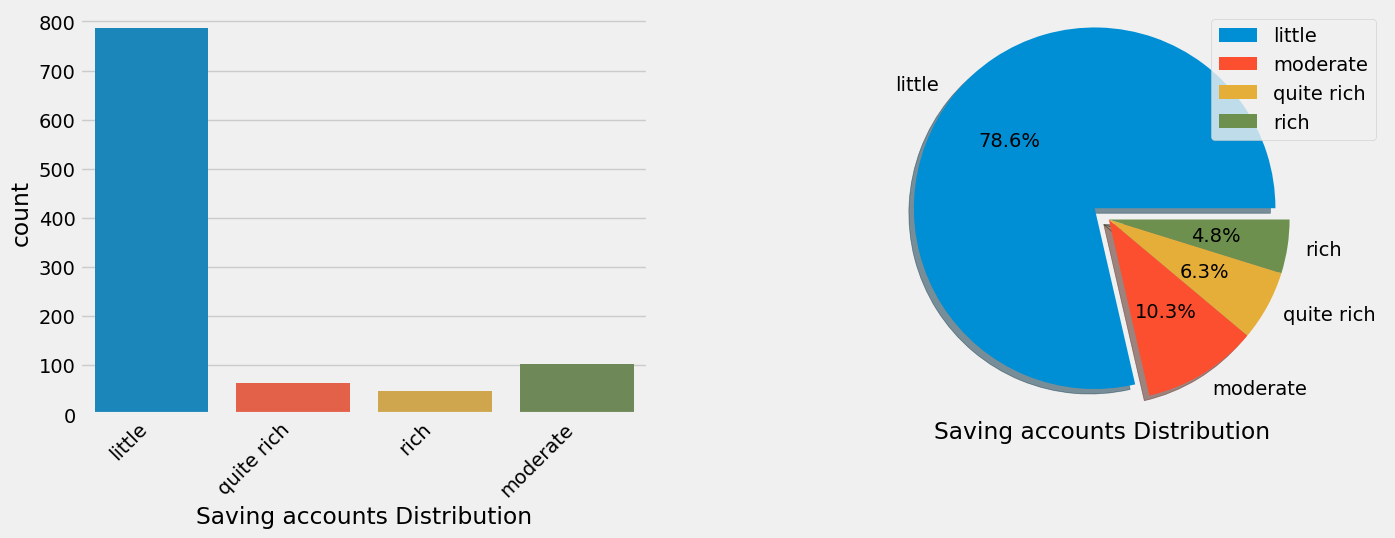
- The following factors of the customers favor an excellent loan: owning a house, small saving accounts, credit to buy radio/TV, and little checking account.
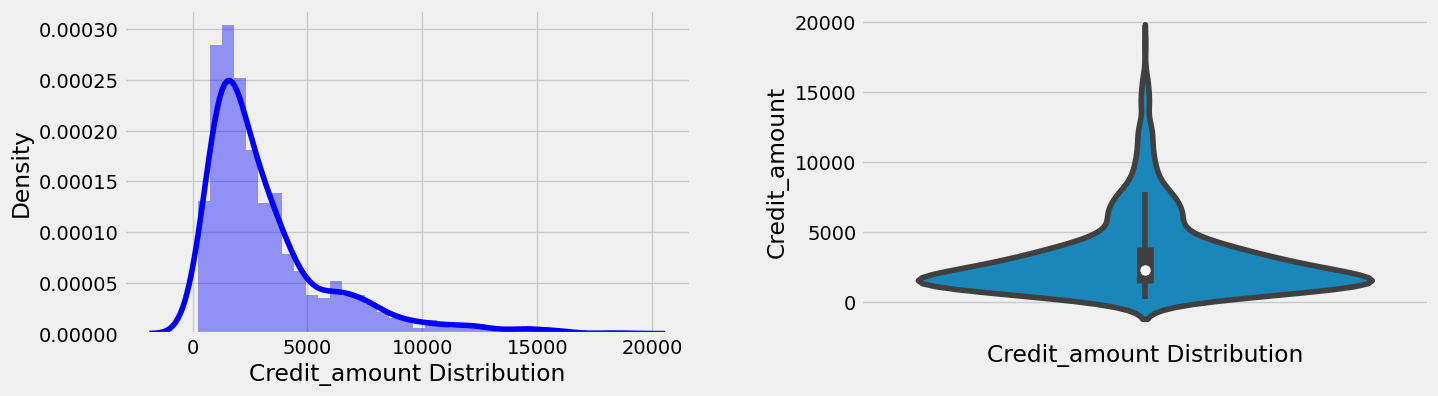
- The conditions of credit application for a bad loan are a High credit amount borrowed (>11000) and a high duration.
- The probability that a credit application is a bad loan increases for amounts more significant than 3000 or with a duration greater than 25 months.
- Credit amount and Duration attributes are strongly correlated (0.62). Credit amount and Duration attributes show a negative correlation coefficient of -0.15 and -0.21, respectively (Larger credit amount and duration implies higher loan risk).
- All categorical attributes have a significant relationship with the target variable (Risk) except ‘Purpose’ attribute. In addition, saving account has the highest affect on the Risk (lowest p-value).
- Random Forest exhibits the best performance metrics (Accuracy =0.72, Recall = 0.94, Precision = 0.73, F1-score = 0.82, and ROC-auc = 0.56).
In the domain of finance and banking, accurate and effective risk prediction for credit customers is an imperative task. It is crucial for banks and financial institutions to understand the likelihood of their customers defaulting on a loan, to not only protect the institution’s financial health but also to comply with regulatory norms.
The development of data analysis and predictive model based involves the following items:
- Data analysis: Univariate analysis (numeric and categoric attributes), Bivariate analysis, Correlation of variables, Chi Square Test.
- Data Processing: Outlier handling, one hot encoding, data normalization, stratified cross validation (imbalanced classes).
- Machine learning: Logistic regression, K-Neighbors classifier, Naive Bayes classifier, Decision Tree Classifier, Random Forest Classifier, XGBoost, AdaBoost Classifier.
- Hyperparameter tunning: Grid search methodology
Banks and Financial Institutions: These entities benefit from more precise risk assessments, which allows for better decision-making in granting loans and setting interest rates. By accurately predicting credit risk, they can minimize potential losses due to defaults and optimize their loan portfolio for better profitability.
Customers/Borrowers: Accurate credit risk prediction models contribute to fair and transparent lending practices.
Investors: Investors in banks or financial institutions will benefit from a better-managed credit portfolio, leading to healthier financial statements, thereby reducing investment risk.
Fintech Companies: Companies that develop and provide credit risk prediction models can benefit from the validation and potential success of their technologies in the market.
The Germat Credit data was obtained from Kaggle.
Data Attributes: The original dataset contains 1000 entries with 20 categorial/symbolic attributes, where each entry represents a person who takes a credit by a bank. Each person is classified as good or bad credit risks according to the set of attributes.
The features anda data type are:
- Age (numeric)
- Sex (text: male, female)
- Job (numeric: 0 – unskilled and non-resident, 1 – unskilled and resident, 2 – skilled, 3 – highly skilled)
- Housing (text: own, rent, or free)
- Saving accounts (text – little, moderate, quite rich, rich)
- Checking account (numeric, in DM – Deutsch Mark)
- Credit amount (numeric, in DM)
- Duration (numeric, in month)
- Purpose (text: car, furniture/equipment, radio/TV, domestic appliances, repairs, education, business, vacation/others)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}